

Einleitung
Ein „Captcha“ (das Kunstwort steht für „Completely automated public Turing test to tell computers and humans apart“ oder auf Deutsch etwa „vollautomatischer öffentlicher Turing-Test zur Unterscheidung von Computern und Menschen“) ist im Prinzip eine Methode um festzustellen, ob man es in einer bestimmten Situation mit einem Mensch oder einer Maschine zu tun hat.
In der Regel werden Captchas benutzt, um eine zusätzliche Sicherheit für Formulare im Internet zu schaffen, weil hier am häufigsten Spambots eingesetzt werden.
In diesem Artikel erfahren Sie einiges über die Entwicklung und die Hintergründe von ReCaptcha und über die datenschutzrechtlichen und technischen Konsequenzen des Einsatzes. Danach gehe ich noch auf die möglichen Alternativen zu ReCaptcha ein.
Ich wünsche Ihnen viel Spaß bei der Lektüre. Wenn Sie Ergänzungen oder Anmerkungen zu diesem Artikel haben, würde ich mich freuen. Benutzen Sie in diesem Fall bitte die Kommentarfunktion am Ende des Artikels.
Die Geschichte des Captchas
Die früheren Captchas waren im Allgemeinen Frage-Antwort-Tests, bei denen der Benutzer eine Aufgabe lösen muss. Dabei besteht die Frage häufig aus einem Bild, in der Antwort muss der Benutzer dann den Inhalt des Bildes beschreiben. Für einen Computer ist die Lösung solcher Aufgaben nicht ganz unkompliziert, weil Sie dafür zunächst einmal einen Algorithmus zur Mustererkennung benötigen.
Die ersten Versionen
Ein Beispiel für eines der früheren Captchas, an die Sie sich möglicherweise noch erinnern können, sehen Sie hier. Dieses Beispiel stammt übrigens aus einer alten Version von WordPress.

Im Jahr 2006 ergab eine Hochrechnung der „Carnegie Mellon University“, dass Internet-Nutzer weltweit pro Tag ungefähr 150.000 Stunden damit verbringen, Captchas zu lösen. Als Konsequenz kam ein Informatiker namens Luis von Ahn auf die Idee, dass man diese Arbeitsleistung auch sinnvoll einsetzen könne, und entwickelte die erste Version eines Systems, das er als „ReCaptcha“ bezeichnete.
Das erste ReCaptcha
Die Idee dahinter war simpel und genial. Da immer mehr Informationen (Bücher, Artikel usw.) digitalisiert werden mussten, konnte man doch die bei der Digitalisierung durch die Software nicht erkannten Wörter scannen und von Menschen in Form eines Captchas lösen lassen. Und die Idee funktionierte hervorragend. Zum Beispiel trug der Dienst erheblich dazu bei, dass ab 2009 die New York Times zwanzig komplette Jahrgänge innerhalb von ein paar Monaten digitalisieren konnte. Ein Beispiel für eines dieser ursprünglichen ReCaptchas sehen Sie hier, das Wort auf der linken Seite ist das eigentliche Captcha, das auf der rechten Seite das gescannte Wort (auf diesem ReCaptcha finden Sie auch noch den ursprünglichen Slogan „stop spam. read books.“).

Im September 2009 kaufte Google das Unternehmen ReCaptcha. Google nutze die Mustererkennung zunächst für sein Projekt „Google Books“, für das Millionen von Büchern digitalisiert werden mussten. Später wurde das System dann auch für die Digitalisierung von Hausnummern und Straßennamen aus „Google Street View“ genutzt. Auch in der Version 2 von ReCaptcha kam die Erkennung nach wie vor zum Einsatz. Ein Beispiel für Version 1 und Version 2 von ReCaptcha sehen Sie unten.


Da dieses System aber ganz erhebliche Nachteile in Bezug auf die Barrierefreiheit (speziell für sehbehinderte Menschen) hatte, die Akzeptanz der Nutzer ganz erheblich nachließ und die Lösung der Captchas durch Maschinen immer mehr voranschritt, musste ein neues System von ReCaptcha her.
ReCaptcha V2
Die Entwicklung zur Lösung dieser Probleme begann im Jahre 2013 mit dem sogenannten „No Captcha ReCaptcha“. Diese Versionen von ReCaptcha verwenden verhaltensorientierte Analysen (unter anderem auf Basis der bisherigen Browser-Interaktionen des Benutzers) um eine Wahrscheinlichkeit dafür zu errechnen, ob der Benutzer ein Mensch ist.
Wenn der Algorithmus der Ansicht ist, dass der Benutzer ein Mensch ist, reicht ein Mausklick auf das Captcha aus. Ansonsten wird ein Fenster mit einer Frage oder einer anderen Aufgabe eingeblendet, die gelöst werden muss (siehe Beispiele unten). Der neue Mechanismus wird seit 2014 von Google in öffentlich zugänglichen Diensten verwendet. Auch die Bilder in den neueren Versionen stammen übrigens aus Street View und helfen Google bei der Erfassung der Daten.

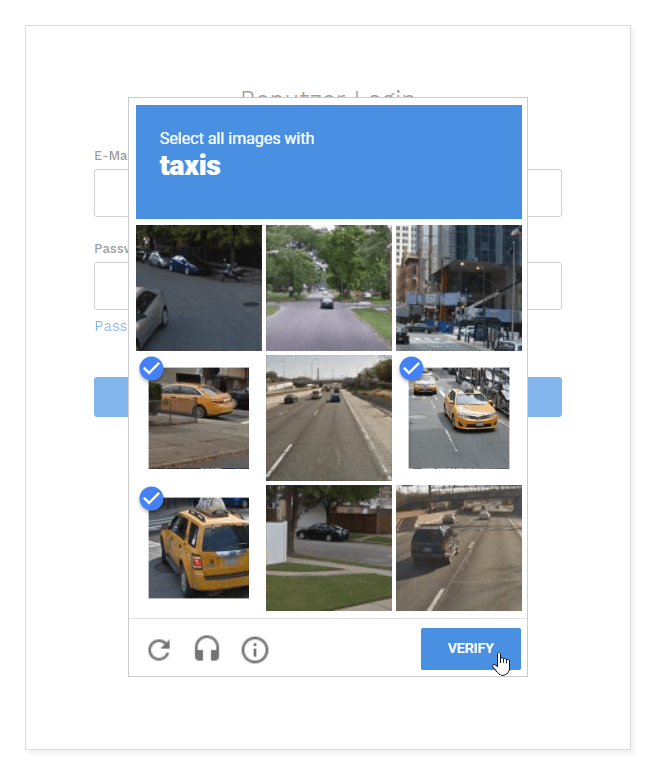
Spätere Versionen von ReCaptcha V2 konnten dann bereits unsichtbar in die jeweiligen Seiten eingebaut werden und erledigten die Überprüfung im Hintergrund („Invisible ReCaptcha“). Hier war dann nicht einmal mehr der Mausklick notwendig.
ReCaptcha V3
Die Version 3 von ReCaptcha arbeitet auf der Basis eines im Hintergrund laufenden JavaScript-Tools und das Nutzerverhalten analysiert. Jede getätigte Aktion wird mit einem Wert zwischen 0 und bewertet (umso näher der Wert an 0 liegt, desto höher ist die Wahrscheinlichkeit eines Bots). Jeder Website-Betreiber kann dabei für seine Website einen Grenzwert festlegen, ab welchem weitere Zugriffe verhindert werden (der Standardwert liegt bei 0,5).
Datensammlung in neuen Dimensionen
Eine kaum vermeidbare Folge der mit der Version 2 von ReCaptcha eingeführten Verhaltensanalysen ist die Tatsache, dass Google für diese Analyse so viel Daten wie irgend möglich über die Aktionen eines bestimmten Benutzers benötigt. Um diese Daten zu bekommen, legt Google sein Augenmerk darauf, an möglichst vielen Stellen im Netz präsent zu sein. Und das ist bereits recht weit fortgeschritten.
Laut der aktuellen Statistik von BuildWith (Stand September 2019) nutzen aktuell knapp 4,5 Millionen Websites ReCaptcha. Und damit hat Google zumindest schon einmal eine ziemlich klare Idee davon, welche Websites ein Benutzer so aufsucht. Und dazu kommen dann noch einmal knapp 28 Millionen Websites mit Google Analytics, die noch präzisere Daten sammeln.
Und mit Google ReCaptcha in der Version 3 geht das Ganze dann noch einmal einen Schritt weiter. Weil ReCaptcha V3 nach den Empfehlungen von Google nämlich auf allen Seiten einer Website im Hintergrund laufen und Aktionen der Benutzer aufzeichnen soll. Damit erhält der Website-Betreiber die Möglichkeit, die Aktionen seiner Benutzer recht genau zu analysieren. Und natürlich weiß auch Google dadurch noch etwas genauer, was der einzelne Benutzer auf einer Website so treibt.
Die Datenschutz-Problematik
Gegen diese Datensammel-Wut wäre grundsätzlich auch gar nicht so viel einzuwenden, wenn Sie nur dazu genutzt würde, das Internet sicherer zu machen. Aber dem ist leider nicht so.
Aus dem Surfverhalten eines bestimmten Benutzers lässt sich nämlich recht einfach ein psychologisches Profil dieses Benutzers erstellen. Und dieses psychologische Profil wiederum lässt sich hervorragend für Werbung aller Art und für eine bewusste Beeinflussung verschiedener Zielgruppen verwenden. Google selbst nutzt dieses sogenannte „Targeted Advising“ in seinem Werbedienst „Google AdSense“.
Und auch gegen diese Art der zielgerichteten Werbung lässt sich nicht so sehr viel einwenden. Denn ein Unternehmen wie Google stellt eine Menge sehr nützlicher Werkzeuge für einen Großteil der Weltbevölkerung mehrheitlich gratis zur Verfügung und trägt enorm viel zur Verbesserung der Sicherheit im Internet bei. Und diese Dienstleistung von Google muss natürlich in irgendeiner Form finanziert werden.
Nur dass sich hier ein größeres datenschutzrechtliches Problem auftut. Und das liegt darin, dass Google letztendlich nichts darüber verlauten lässt, welche Daten von Ihnen gesammelt und wie Sie verwendet werden. Und dass Sie als Benutzer von dieser Sammlung von Daten beim Surfen im Internet auch kaum etwas mitbekommen.
Die Dimensionen eines möglichen Datenmissbrauchs
Aber das allergrößte Problem liegt darin, dass diese enormen Datenmengen auch missbräuchlich genutzt werden könnten. Und dass diese Daten brisant genug sind, um im Falle eines Missbrauchs enorme Auswirkungen haben zu können.
Die möglichen Auswirkungen haben sich gezeigt, als bei einem anderen der großen Datensammler dieser Planeten, bei Facebook, Daten über das Surfverhalten der Benutzer von einer Firma namens „Cambridge Analytica“ missbräuchlich genutzt wurden.
Über diesen Skandal finden Sie bei Interesse mehr Informationen in meinem Artikel „Der Skandal um Cambridge Analytica und seine Folgen“. Und über die Methoden der Erstellung psychologischer Profile finden Sie weitere Informationen in meinem Artikel „Psychometrie – Die neue Waffe der Politik“.
Technische Folgen des Einsatzes von ReCaptcha
Neben den Aspekten des Datenschutzes gibt es auch in technischer Hinsicht einige Probleme beim Einsatz von ReCaptcha.
Ich bin bei einem eigenen Test mit einer Standard-Website unter WordPress auf folgende Zahlen gekommen. Der Einsatz von ReCaptcha verlangsamte die Ladezeit meiner Website um durchschnittlich 350 Millisekunden, im besten Fall waren es knapp über 250 Millisekunden, im schlimmsten mehr als 3 Sekunden. Außerdem erhöhte sich die Anzahl der HTTP Requests um (je nach Konfiguration) zwischen 11 und 20. Die Werte habe ich übrigens mit „GTMetrix“ und den „Pingdom Tools“ ermittelt. Andere im Internet verfügbare Tests kommen da übrigens zu sehr ähnlichen Ergebnissen.
Bei Ladezeiten von unter 1 Sekunde für eine gut optimierte Website (die Hauptseite meiner Website lädt beispielsweise deutlich schneller, siehe Screenshots unten) ist eine solche Verschlechterung nicht akzeptabel.


Auch aus technischer Sicht spricht also einiges gegen den Einsatz von ReCaptcha.
Die möglichen Alternativen
Google ReCaptcha ist vermutlich die perfekteste Lösung zur Verhinderung von Spam und eröffnet gleichzeitig (besonders in der Version 3) sehr gute Möglichkeiten zur Analyse des Verhaltens Ihrer Website-Besucher.
Aber es bereitet gleichzeitig eben auch erhebliche Probleme in Bezug auf den Datenschutz und auf die Performance.
Die Entscheidung für oder gegen den Einsatz von ReCaptcha muss daher jeder Website-Betreiber für sich selbst treffen.
Falls Ihre Entscheidung gegen den Einsatz von ReCaptcha ausfallen sollte, werden Sie zur Vermeidung von Spam (besonders Kommentar-Spam wird Sie garantiert treffen) eine Alternative suchen müssen. Und deswegen möchte ich Ihnen hier einen anderen Lösungsansatz und einige Plug-Ins vorstellen, die diesen Lösungsansatz nutzen.
Das Prinzip des „Honeypot“
Die Idee hinter dem sogenannten „Honeypot“ (der englische Begriff bedeutet eigentlich „Honigtopf“, wird im Bereich der Computersicherheit aber als Synonym für ein „Scheinziel“ verwendet) ist, wie die meisten guten Ideen, sehr einfach.
Im Bereich der Formularverarbeitung ist ein „Honeypot“ ganz einfach ein zusätzliches Eingabefeld (mit einem Namen, der Wichtigkeit vermuten lässt), das einem Formular hinzugefügt wird. Dieses Eingabefeld ist für einen normalen Benutzer nicht sichtbar und kann von ihm deswegen auch nicht ausgefüllt werden.
Solche verdeckten Formularfelder sind übrigens keine Seltenheit, sie werden für vielerlei Funktionen angewandt.
Im Gegensatz zu einem menschlichen Benutzer „sieht“ ein Bot das Formular nun allerdings nicht, sondern kann nur den dahinterliegenden HTML-Code analysieren und eine Eingabe simulieren. Und füllt deswegen das zusätzliche verdeckte Feld (unseren „Honeypot“) gleich mit aus.
Und deswegen müssen alle über dieses Formular übertragenen Daten, bei denen dieses spezielle Feld ausgefüllt wurde, von einem Bot stammen. Und können deswegen bedenkenlos direkt als Spam gekennzeichnet oder gelöscht werden. Eigentlich ganz einfach, oder?
Kommentar-Spam
Ich kenne momentan zwei Plug-Ins, die das System des „Honeypot“ zur Bekämpfung von Kommentar-Spam verwenden. Aber wahrscheinlich gibt es noch einige mehr, die ich nicht kenne.
Antispam Bee
Das Plug-In „Antispam Bee“ wurde speziell für deutsches bzw. europäisches Recht konzipiert. Meiner (rechtsunverbindlichen) Meinung nach ist es datenschutzrechtlich unbedenklich einsetzbar, solange man auf zwei Funktionen verzichtet.
Die Option „Öffentliche Spamdatenbank berücksichtigen“ sorgt für eine Übertragung der Daten an einen Drittserver, was datenschutzrechtlich bedenklich ist. Und die Option „Kommentare nur in einer Sprache zulassen“ überträgt zumindest Teile des Kommentars an die Google-Übersetzungsserver, was meiner Meinung nach datenschutzrechtlich ebenfalls nicht ganz unbedenklich ist.
Außerdem schleppt das Plug-In für meinen Geschmack etwas viel Ballast mit sich herum. Aber es bietet dafür auch sehr viele zusätzlich Funkionen. „Antispam Bee“ ist definitiv ein tolles Plug-In, das ohne die beiden oben genannten Funktionen bedenkenlos eingesetzt werden kann.
Honeypot for WP Comment
Ein ziemlich neues Plug-In, dass mir persönlich nach den ersten Eindrücken sehr gut gefällt, ist „Honeypot for WP Comment“. Und zwar hauptsächlich deswegen, weil es sich auf eine einzige Funktion beschränkt und auf unnötigen Ballast verzichtet. Es benötigt deswegen keinerlei Einstellung, sondern muss einfach nur aktiviert werden.
Das Plug-In bindet in die Kommentier-Funktion von WordPress einen „Honeypot“ ein. Und markiert ganz einfach jeden Kommentar als Spam, bei dem dieses Feld ausgefüllt wurde.
Und gerade weil es auf jede Zusatzfunktion verzichtet und deswegen kaum Ressourcen benötigt, ist dies Plug-In für die Vermeidung von Kommentar-Spam momentan meine erste Wahl.
Das Plug-In ist übrigens auf dieser Website im Einsatz. Sollte ich im Laufe der Zeit auf Probleme stoßen, werde ich diesen Artikel aktualisieren und auf diese Probleme eingehen.
Formular-Spam
Während Sie in so ziemlich jedem besseren Formulargenerator Google ReCaptcha direkt einbinden können, sieht es bei Einbindungen von automatisierten Lösungen mit „Honeypot“ etwas düsterer aus.
Momentan sind mir die folgenden Formulargeneratoren bekannt, die laut Hersteller die Honeypot-Technik enthalten (die Liste erhebt keinerlei Anspruch auf Vollständigkeit).
- Contact Form 7 (kostenlos)
mit dem Plug-In Honeypot for Contact Form 7 (kostenlos) - WP Forms.(ab US-$ 79 pro Jahr)
- Formidable Forms (ab US-$ 99 pro Jahr)
- Caldera Forms (kostenlos + Premium)
- QuForm² (US-$ 29)
Sie können allerdings mit so ziemlich jedem Formulargenerator ein verstecktes Feld anlegen und die Honeypot-Funktion so zumindest simulieren.
Absicherung der WordPress-Anmeldung
Für die Absicherung der WordPress-Anmeldung ist mir momentan keine Alternative zu Captchas bekannt.
Sie können allerdings einen Großteil eventueller Versuche von Bots einfach dadurch vereiteln, dass Sie die Adresse der WordPress-Anmeldeseite ändern. Das können Sie sehr einfach mit dem kostenlosen Plug-In „WPS Hide Login“ erledigen.





Danke für den beitrag, ich habe jetzt Recaptcha rausgeschmissen und die Webseite lädt deutlich schneller, auch tests bei Pindom und lighthouse zeigen markante Verbesserungen. Ich werde jetzt mal das Honeypot Plugin für contact7 ausprobieren.
THX